책 발췌 – 머신러닝 애플리케이션 테스팅 by Gayathri Mohan
출처: 2022년, Full Stack Testing - A Practical Guide for Delivering High Quality Software by Gayathri Mohan, Chapter 13. Introduction to Testing in Emerging Technologies
한줄요약: 머신러닝에 대해 간략히 소개하고 머신러닝 애플리케이션에 고유한 테스팅 측면을 논한다.
머신러닝(Machine Learning) 소개
우리가 애플리케이션을 개발할 때 컴퓨터가 실행할 일련의 명령(instructions)을 코딩한다. 적어도 지금까지 컴퓨터가 작동하는 방식은 이것이었다. 그래서 명시적으로 프로그래밍되지 않고도 컴퓨터가 경험을 통해 학습할 수 있다는 말은 매우 흥미롭다. 이것이 무엇을 의미하는지 이해하기 위해 소셜 미디어 앱의 악성 콘텐츠 필터(abusive content filter)를 예로 들어 보자. 이는 기존 프로그래밍과 머신러닝 접근 방식의 차이점을 보다 정확하게 이해하는 데 도움이 된다.
기존 프로그래밍 방식으로 악성 콘텐츠 필터를 구축하려면, 먼저 콘텐츠를 악성 콘텐츠로 식별하는 기준(criteria)을 나열하고 이를 규칙(rules)으로 코딩한 다음 이를 트리거하는 게시물을 제거해야 한다. 예를 들어, 자살, 섹스, 경고 트리거 등과 같은 키워드를 확인하도록 코드를 작성할 수 있다. 또한 알려진 악용자의 사용자 ID를 확인 후 해당 콘텐츠를 악성으로 표시하고 피드를 자동으로 건너뛸 수 있다.
하지만 이것으로 충분할까? 우리가 일련의 단어 목록을 악성으로 표시하는 규칙을 코딩하면 악용자는 이를 우회하기 위해 신속하게 새로운 단어를 도입한다. 마찬가지로 기존 계정이 제한되면 악의적인 사용자는 콘텐츠를 보낼 새 계정을 설정한다. 규칙 자체가 비결정적인(nondeterministic) 문제 공간에서 전통적인 프로그래밍 접근 방식을 사용하여 완벽한 솔루션을 작성하는 것은 매우 어려우며, 여기가 바로 머신러닝이 도움의 손길을 뻗치는 곳이다.
그림 13-1에서 볼 수 있듯이 머신러닝 프로그래밍 접근 방식을 사용하면 악의적이거나 악의적이지 않은 것으로 분류된 엄청난 양의 과거 데이터를 머신러닝 모델에 공급한다. 이를 모델 훈련이라고 한다. 이 모델은 기본적으로 수학적 알고리즘이며, 데이터로부터 두 콘텐츠 유형 간의 차이점을 학습한다. 이는 어떤 면에서는 인간의 두뇌가 학습하는 방식과 유사하다. 우리는 수년에 걸쳐 다양한 각도에서 다양한 크기, 모양, 색상의 많은 사과를 보게 되고, 사과를 찾는 데 능숙해진다. 마찬가지로 우리가 사과와 오렌지의 차이를 구별하는 방법도 배운다.
일단 모델이 훈련되면 새 게시물이 악성 콘텐츠인지 여부를 알아낼 수 있다. 인간 아이가 그러하듯이 처음부터 모든 답을 다 맞히지는 못할 수도 있다. 보다 다양한 데이터 세트로 지속적으로 모델을 훈련해야 하며, 레이블이 지정되지 않은 데이터로 테스트하여 모델의 정확성을 계속 평가해야 한다. 모델의 정확도를 테스트하는 데 사용되는 레이블이 없는 데이터를 테스트 세트(test set)라고 하며, 모델 훈련에 사용되는 데이터를 훈련 세트(training set)라고 한다. 모델의 정확도가 충분히 높으면 프로덕션에 배포된다. 또한 모델은 새로운 단어와 변형을 포착할 수 있도록 프로덕션의 새로운 콘텐츠로 지속적으로 학습된다.
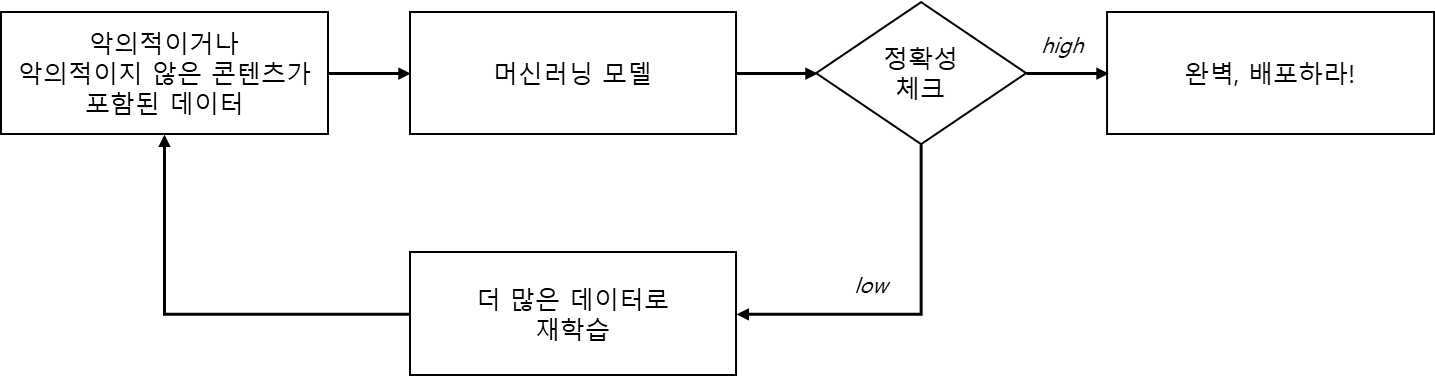
머신러밍 프로그래밍 워크플로우를 요약하면 먼저 많은 데이터를 수집하고, 데이터에 적절하게 태그를 지정하고, 이를 훈련 세트와 테스트 세트로 나누고, 훈련 세트를 사용하여 머신러닝 모델을 훈련하고, 테스트 세트로 모델의 효율성을 평가하고, 배포를 하고, 다시 훈련을 계속한다. 이러한 작업에 도움이 되는 머신러닝 프레임워크로는 scikit-learn, PyTorch 및 TensorFlow가 널리 알려져 있다.
머신러닝 애플리케이션 테스팅
대부분의 머신러닝 애플리케이션은 서비스에 머신러닝 컴포넌트가 통합된 일반적인 서비스 기반 아키텍처(service-based architecture)를 채택한다. 악성 콘텐츠 필터 예에서 서비스 기반 흐름이 다음과 같을 수 있다. 사용자가 새 게시물을 만들면 UI는 해당 게시물을 콘텐츠 서비스로 보내 게시물이 악성인지 여부를 머신러닝 모델에서 확인한다. 모델이 콘텐츠를 악성으로 식별하면 콘텐츠 서비스는 UI에 해당 콘텐츠를 숨기도록 지시한다. 일반적인 서비스 지향 아키텍처를 테스트하는 기존 테스팅 접근 방식과 함께 전체 애플리케이션 테스팅을 커버하려면 다음 측면을 포함해야 한다.
훈련 데이터 검증(Validating training data)
모델에 공급되는 데이터가 그 모델의 품질을 크게 좌우한다. 데이터 품질이 좋지 않으면 모델 품질도 좋지 않다. 따라서 머신러닝 애플리케이션에서는 입력 데이터 품질에 중점을 두는 것이 중요하다. 모델을 훈련하려면 엄청난 양의 데이터가 필요하기 때문에 다양한 소스(예: 공개 데이터베이스, 공개 웹사이트의 스크랩, 다양한 웹사이트의 사용자 입력 데이터, 시스템 로그 등)에서 데이터를 얻는다. 이로 인해 일반적으로 다양한 형태와 모양의 데이터(기본적으로는 어수선하고 무질서한 혼란 더미)가 남게 된다. 우리 예에서 데이터 소스는 소셜 미디어의 과거 게시물이었다. 이러한 게시물에는 텍스트뿐 아니라 이미지, 비디오, GIF, 댓글, 태그 등이 포함될 수 있다. 이들 중 일부는 크기, 파일 형식, 색상 그라데이션 등등이 다를 수 있다. 이처럼 일관되지 않은 데이터를 모델에 공급하면 모델이 악성 콘텐츠에 대한 특징에 집중하고 구별을 정확하게 학습하기 어렵다. 따라서 입력 데이터를 청소하고, 노이즈를 제거하고, 표준화된 형식으로 변환한 다음 훈련을 위해 모델에 공급하는 것이 일반적이다. 이 청소(cleansing) 및 변환(transformation) 로직이 철저하게 테스트되어야 한다.
모델 품질 검증(Validating model quality)
모델의 품질은 오류율(error rates), 정확도(accuracy), 혼동 행렬(confusion matrices), 정밀도(precision), 재현율(recall) 등 다양한 메트릭으로 측정된다. 각각을 계산하는 방법이 있다. 우리 예에서는 정밀도와 재현율을 사용한다고 가정하자. 정밀도(Precision)는 모델이 결과를 올바르게 예측하는 능력을 나타낸다. 즉, 참양성(true positives)과 거짓양성(false positives)의 총 수 중 참양성의 수를 나타낸다. 예를 들어 모델이 100개의 게시물을 악의적인 게시물로 식별하였고 99개가 실제로 악의적인 게시물이였다면 정밀도 지수는 0.99이다. 반면 재현율(Recall)은 얼마나 많은 실제 악성 게시물이 모델에 의해 올바르게 식별되었는지를 알려주는 지표로 참양성(true positives)과 거짓음성(false negatives)의 총 수 중 참양성의 수를 나타낸다. 모델이 총 110개의 악성 게시물 중 99개를 악성 게시물로 올바르게 식별한 경우 재현 지수는 0.90이다.
모델 편향 검증(Validating model bias)
품질이 낮은 데이터도 문제이지만 모델의 편향은 문제를 더욱 악화시킨다. 최근 트위터의 이미지 크롭 머신러닝 알고리즘이 흑인보다 백인의 얼굴을 선호하여 대중의 비판에 직면했고, 결국 회사는 해당 자동 크롭 방식을 포기하게 되었다. 이러한 편향은 입력 데이터에서 모델로 스며든다. 입력 데이터에 특정 인구 통계를 나타내는 대규모 샘플 세트가 있는 경우 모델은 해당 인구 통계에 편향된다. 따라서 입력 데이터와 머신러닝 모델 모두에서 편향을 테스트하는 것이 중요하다.
통합 검증(Validating integrations)
세 가지 계층 간의 통합(특히 데이터 계층 및 모델 계층, 모델 계층 및 API 계층)을 기존 계약 및 통합 테스팅 방식을 사용하여 테스트해야 한다.